Úloha 1. (10 bodů)
Na vstupu je dán
vzestupně setříděný (pythonovský) seznam
a celá čísla
Naším cílem je určit všechny prvky seznamu
Vstup: Vzestupně setříděný (pythonovský) seznam
Výstup: indexy levy a pravy takové, že None pokud takové indexy neexistují
Navrhněte postup, jak správně vyřešit úlohu s co nejlepší časovou a prostorovou složitostí (měřeno nejhorším případem) vzhledem k délce vstupního seznamu.
(a) Popište algoritmus (včetně datových struktur, které případně budete používat). Programový kód není povinný, slovní vysvětlení zvoleného postupu řešení naopak povinné je. Nepoužívejte prosím žádné netriviální datové struktury (jako jsou např. datové typy dictionary či set v jazyce Python), jejichž algoritmus sami nepopíšete a neodvodíte jeho časovou složitost.
(b) Zdůvodněte správnost algoritmu.
(c) Odvoďte časovou a prostorovou složitost (v nejhorším případě). Do prostorové složitosti počítejte jen paměť, do níž se zapisuje.
Příklady:
vstup:
[-22, -8, -5, 0, 1, 2, 7, 20, 20, 20, 100, 200, 200] -1 100
výstup: 3 10
vstup:
[-22, -8, -5, 0, 1, 2, 7, 20, 20, 20, 100, 200, 200] -50 5
výstup:0 5
vstup:
[-22, -8, -5, 0, 1, 2, 7, 20, 20, 20, 100, 200, 200] 333 500
výstup: None
Poznámka: Za triviální řešení v čase
Úloha 2. (10 bodů)
Navrhněte efektivní algoritmus, který pro zadaný binární strom určí jeho nevyváženost, tj. největší celé nezáporné číslo
Na obrázku je binární strom o nevyváženosti tři, protože pro vrchol
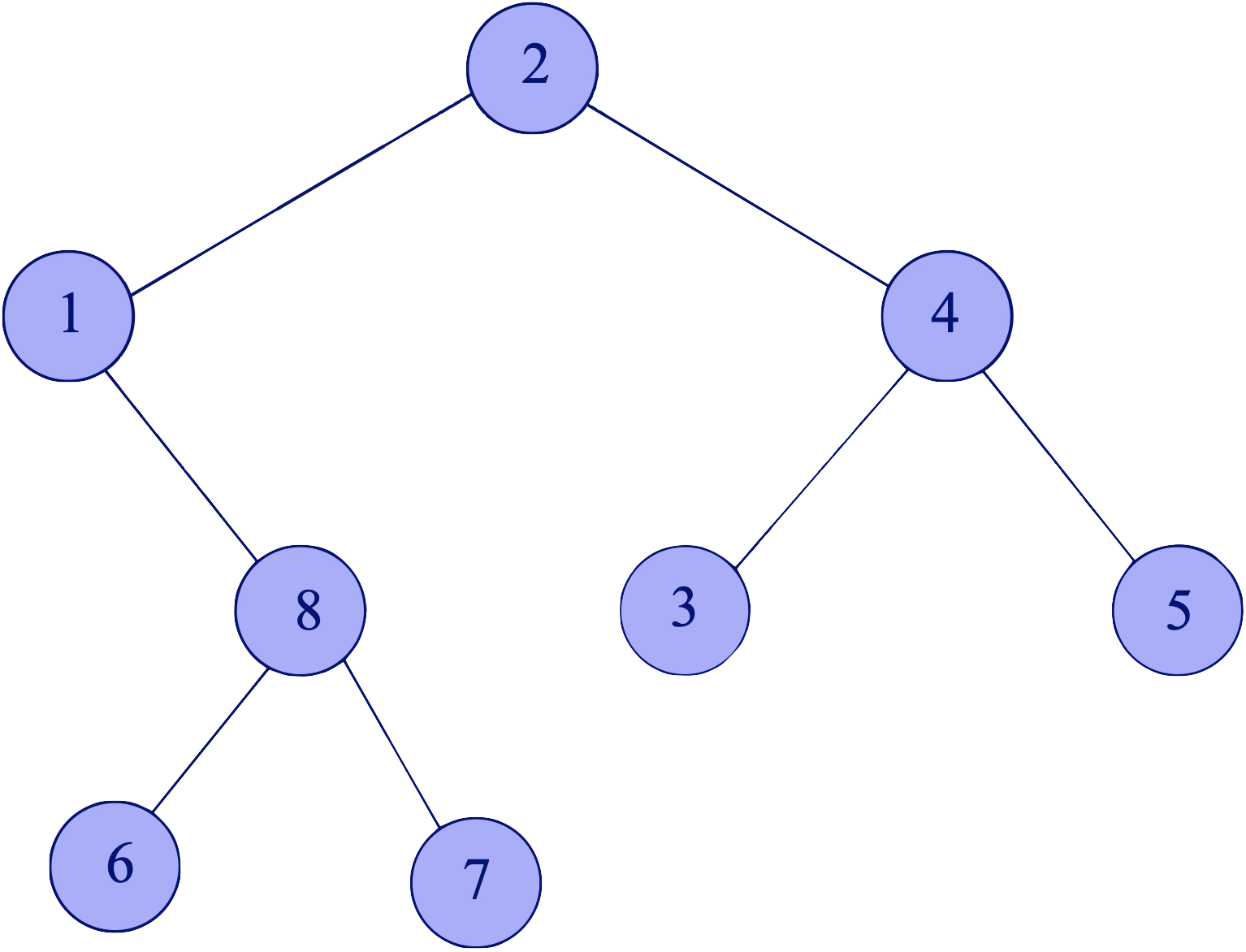
Poznámka: Zajímá nás pouze tvar stromu. Vůbec nehledíme na hodnoty uložené ve vrcholech stromu (atribut data).
(a) Svoje řešení zapište jako funkci v Pythonu, využijte definici třídy pro vrchol binárního stromu i hlavičku funkce uvedené níže a váš kód prosím opatřete komentáři,
(b) zdůvodněte správnost,
(c) odvoďte časovou složitost (v nejhorším případě).
class VrcholBinStromu:
"""třída pro reprezentaci vrcholu binárního stromu"""
def __init__(self, data = None, levy = None, pravy = None):
self.data = data # data
self.levy = levy # levé dítě
self.pravy = pravy # pravé dítě
def nv(koren : VrcholBinStromu):
"""
koren : kořen binárního stromu
vrátí : nevyváženost zadaného stromu
"""
Úloha 3. (10 bodů)
Rozhodněte zda platí, své odpovědi vždy zdůvodněte.
(a) (5 bodů) Profesor Hammerstein se na přednášce otázal studentů, co lze říci o časové složitosti následujícího problému:
Vstup: Odkazy na začátky dvou setříděných spojových seznamů, které obsahují celkem n prvků. Můžete předpokládat, že v žádném seznamu se prvky neopakují.
Výstup: Počet prvků takových, že každý se vyskytuje v obou seznamech současně.
Steve soudí, že v existuje algoritmus, který problém vyřeší v čase
Bill se domnívá, že časová složitost problému je
Ada si myslí, že časová složitost problému je
Kteří studenti mají pravdu a kteří nikoliv (Steve - ANO / NE, Bill - ANO / NE, Ada - ANO / NE)? Svoji odpověď zdůvodněte!
(b) (5 bodů) Strom hry dvou hráčů byl vygenerován do hloubky 3, všechny vrcholy v této hloubce byly ohodnoceny statickou ohodnocovací funkcí a hodnoty zbývajících vrcholů byly spočítány minimaxovým algoritmem. V bílých vrcholech je na tahu hráč maximum, v černých minimum. Výpočet bychom rádi zrychlili metodou alfa-beta prořezávání.
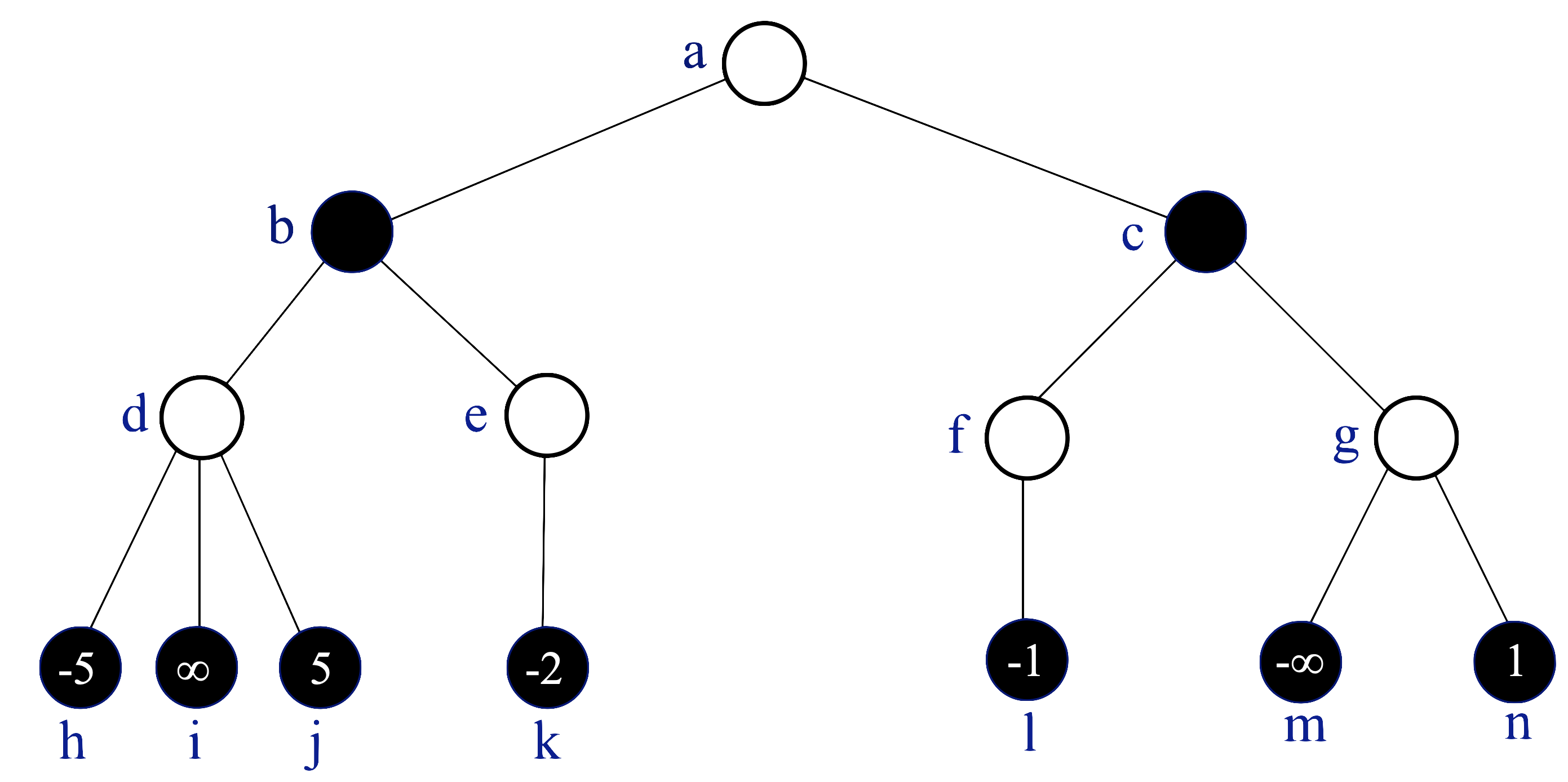
Jaká bude minimaxová hodnota kořenu stromu? (odpověď netřeba zdůvodňovat)
V jakém pořadí je třeba procházet strom, abychom se alfa-beta prořezáváním vyhnuli vyhodnocení co nejvíce vrcholů? Pro popis pořadí můžete využít označení vrcholů a,b,c,... Stačí uvést pořadí, v němž budou vrcholy navštíveny, netřeba zdůvodňovat.
Které vrcholy v takovém případě nemusíme navštívit?
Existuje nějaký průchod stromem, kdy alfa-beta prořezáváním nic neušetříme (tj. pro určení minimaxové hodnoty kořene musíme navštívit a ohodnotit všech 14 vrcholů)? Pokud ano, popište ho (použijte označení vrcholů), pokud ne, vysvětlete proč.